En la última década, la inteligencia artificial ha revolucionado la forma en que interactuamos con la tecnología, y un ejemplo destacado de esto son los asistentes conversacionales. Estos asistentes, alimentados por sofisticados modelos de base, permiten interacciones fluídas y naturales con usuarios de todos los sectores, desde la atención médica hasta el servicio al cliente.
La mayoría de estas aplicaciones se ejecutan directamente en los dispositivos personales de los usuarios, como smartphones y computadoras, lo que facilita el procesamiento inmediato de entradas de texto y voz. Sin embargo, el núcleo del procesamiento, donde se realiza la comprensión y generación de lenguaje natural, está basado en la nube, utilizando potentes GPUs. Este modelo mixto combina lo mejor de ambos mundos: la potencia de cómputo de la nube y la rapidez del procesamiento local.
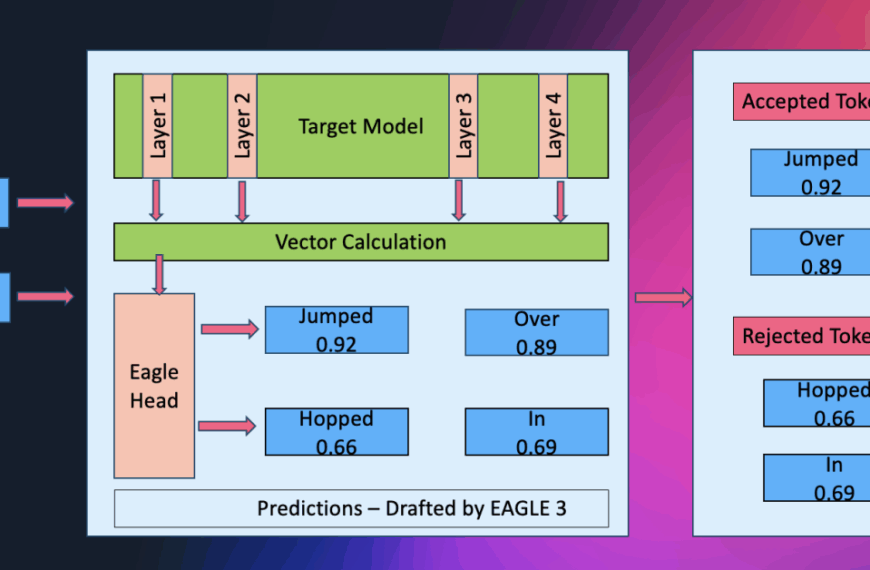
Uno de los mayores desafíos al implementar estos sistemas es la reducción de la latencia en las respuestas, esencial para mantener el flujo natural de una conversación. La latencia se descompone principalmente en dos categorías: la causada por el procesamiento local y el tiempo hasta el primer token, un término que se refiere al período que tarda la nube en generar y enviar la primera parte de la respuesta al usuario. Reducir esta latencia es crucial para optimizar la experiencia del usuario.
Para abordar este reto, se ha propuesto una arquitectura híbrida que utiliza las zonas locales de AWS. Estas zonas son infraestructuras de borde que proporcionan servicios más cerca de grandes concentraciones de usuarios, minimizando el tiempo de transferencia de datos. Al desplegar modelos de inteligencia artificial en estas localizaciones, se logra una notable reducción en la latencia de las respuestas, un avance vital para aplicaciones que demandan interacciones en tiempo real.
Los beneficios de esta estrategia han sido evidentes: pruebas muestran que el uso de zonas locales puede reducir considerablemente la latencia en comparación con los métodos tradicionales que dependen exclusivamente de regiones centrales en la nube. Esta mejora garantiza una experiencia de usuario más natural y eficiente, ya que los tiempos de respuesta se optimizan independientemente de la ubicación geográfica del usuario.
Además, otro aspecto vital en la gestión de estas arquitecturas es la limpieza de los recursos utilizados para evitar costos innecesarios, subrayando la importancia de seguir prácticas recomendadas en la gestión de soluciones en la nube.
En resumen, las zonas locales de AWS se presentan como un avance decisivo en la mejora del rendimiento de los asistentes de inteligencia artificial conversacional, ofreciendo una base sólida para el desarrollo de aplicaciones que requieran baja latencia y una experiencia de usuario superior. Este progreso es un paso más hacia la integración fluida de la inteligencia artificial en nuestra vida diaria, mejorando la interacción humano-máquina de formas antes inimaginables.