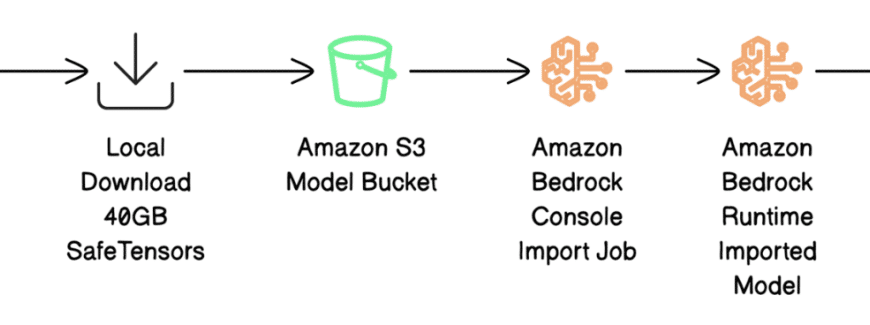
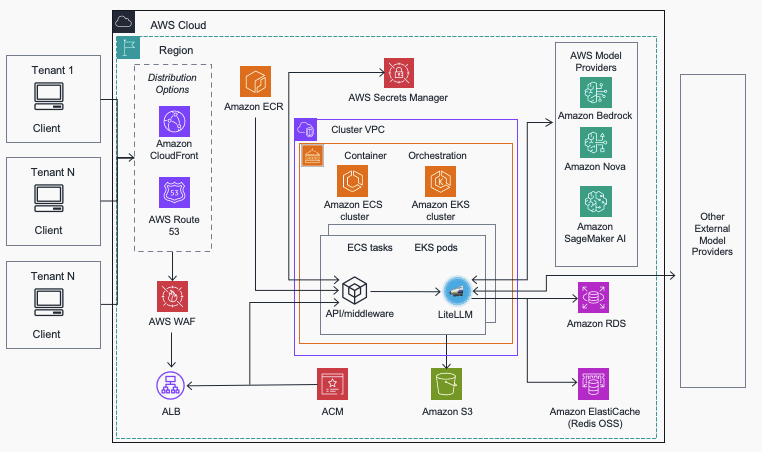
Los chatbots de inteligencia artificial y los asistentes virtuales han experimentado un auge significativo en los últimos años, impulsados por los avances en los modelos de lenguaje de gran capacidad (LLMs, por sus siglas en inglés). Estos modelos, que se entrenan con vastos conjuntos de datos y poseen componentes de memoria en su estructura arquitectónica, pueden entender y contextualizar el contenido textual, lo cual los hace especialmente útiles en diversas aplicaciones.
Entre los usos más comunes de estos asistentes se destacan la mejora de las experiencias de los clientes, el incremento de la productividad y creatividad de los empleados y la optimización de procesos empresariales. Concretamente, los chatbots son herramientas valiosas en áreas como el soporte al cliente, la resolución de problemas y la búsqueda de información tanto interna como externamente.
No obstante, a pesar de sus capacidades, los chatbots enfrentan el desafío de generar respuestas que sean de alta calidad y precisión. Para superar este obstáculo, se utiliza una técnica denominada Generación de Recuperación Aumentada (RAG). El RAG optimiza la salida de un modelo LLM al referenciar una base de conocimiento autorizada, externa a su conjunto de datos de entrenamiento, antes de ofrecer una respuesta definitiva. Además, se emplea la técnica de reordenación para mejorar la relevancia de las respuestas al reorganizar los resultados obtenidos mediante un modelo diferente.
RAG fusiona la recuperación de bases de conocimiento con los modelos generativos para producir texto. Su funcionamiento consiste en recuperar primero respuestas pertinentes de una base de datos para después utilizar estas respuestas como contexto alimentador del modelo generativo, el cual produce la salida final. Este enfoque ofrece muchas ventajas; entre ellas, destaca la capacidad de proporcionar respuestas más coherentes y relevantes, mejorando así el flujo de la conversación. Además, RAG escala de manera más eficiente con grandes volúmenes de datos en comparación con los modelos puramente generativos y no requiere ajuste fino del modelo al incorporar nueva información en la base de conocimientos.
Para localizar una respuesta, RAG emplea una búsqueda vectorial a través de los documentos. La principal ventaja de este método es su rapidez y escalabilidad, ya que en lugar de examinar cada documento, convierte los textos en embeddings, una versión comprimida representada por vectores numéricos, que se almacenan en una base de datos. Posteriormente, la búsqueda vectorial consulta esta base para encontrar similitudes con los vectores de los documentos.
La técnica de reordenación puede perfeccionar aún más las respuestas al seleccionar la mejor opción entre diversas alternativas. Por ejemplo, para construir una solución de respuesta a preguntas, se puede utilizar “El Gran Gatsby”, una novela de 1925 de F. Scott Fitzgerald disponible en Project Gutenberg. Se pueden emplear Bases de Conocimientos para Amazon Bedrock para implementar un flujo de trabajo RAG de extremo a extremo e incorporar embeddings en una colección de búsqueda vectorial de Amazon OpenSearch.
Una vez generadas las preguntas del documento mediante un LLM de Amazon Bedrock y creada la base de conocimientos que contiene el libro, las respuestas se pueden recuperar usando la API de recuperación estándar RAG y también una RAG de dos etapas, que incluye una API de reordenación. Posteriormente, se comparan los resultados de ambos métodos.
Para medir la efectividad del RAG, se emplea un marco llamado RAGAS, que proporciona métricas para evaluar dimensiones como la relevancia de la respuesta, la similitud de la respuesta y la pertinencia del contexto. En pruebas realizadas con “El Gran Gatsby”, la evaluación de un enfoque RAG estándar puede arrojar métricas de relevancia y precisión. Estas se comparan con un enfoque de dos etapas donde se usa una reordenación adicional con modelos avanzados, como el bge-reranker-large, disponible en Hugging Face Hub.
Las conclusiones de estos estudios evidencian que el uso de un modelo de reordenación mejora significativamente la relevancia del contexto, la precisión de la respuesta y la similitud, aunque a costa de un mayor tiempo de latencia. En definitiva, integrar modelos de reordenación con Bases de Conocimientos para Amazon Bedrock puede optimizar la exactitud y relevancia de las respuestas generadas, proporcionando así una mejor experiencia general en el uso de chatbots y asistentes de inteligencia artificial.