La inteligencia artificial sigue ganando terreno en los sectores industriales con su capacidad para automatizar procesos y ofrecer soluciones precisas. En particular, la inteligencia artificial generativa, a través de los modelos de fundación, se presenta como una herramienta esencial para las organizaciones que buscan personalizar sus servicios y productos. Sin embargo, el reto de ajustar estos modelos con efectividad, mientras se gestionan los recursos computacionales, se mantiene como un desafío importante. Nuevos desarrollos, como los modelos lanzados por DeepSeek, evidencian la creciente necesidad de simplificar estas personalizaciones.
El ajuste de los modelos de DeepSeek, en especial, requiere habilidades técnicas avanzadas para redefinir arquitecturas y parámetros. Esto genera un dilema para las empresas que deben equilibrar entre maximizar el rendimiento de los modelos y las limitaciones inherentes a su implementación. Esta situación ha generado una demanda crítica por soluciones más accesibles que faciliten la personalización sin comprometer el desempeño del modelo.
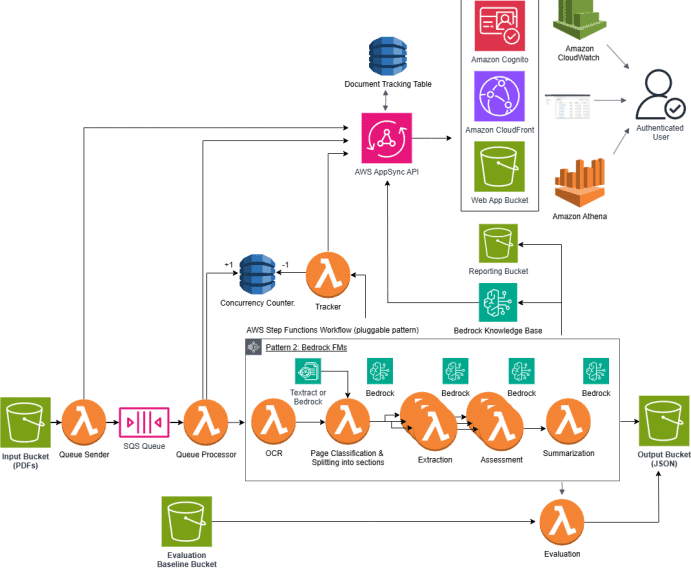
En este contexto, Amazon SageMaker HyperPod ha emergido como una solución prometedora. La plataforma ofrece flujos de trabajo preconstruidos, conocidos como «recetas», que facilitan la personalización de los modelos destilados DeepSeek-R1. Una reciente serie de publicaciones destaca cómo estas recetas pueden simplificar la personalización de estos modelos. En la primera parte de la serie, se expone un método innovador de ajuste fino utilizando el modelo DeepSeek-R1 Distill Qwen 7b, alcanzando una mejora promedio del 25% en las puntuaciones ROUGE, y un destacado 49% en ROUGE-2.
Las recetas de SageMaker HyperPod democratizan el acceso a estas tecnologías avanzadas, permitiendo a científicos de datos y desarrolladores de todas las habilidades entrenar y ajustar modelos de inteligencia artificial generativa en cuestión de minutos. Este enfoque no solo agiliza el proceso de carga de conjuntos de datos de entrenamiento y la aplicación de técnicas de entrenamiento distribuidas, sino que también reduce significativamente el trabajo tedioso asociado a la configuración de modelos.
El diseño modular del sistema permite a las empresas escalar y adaptar sus modelos de manera flexible, siendo especialmente útil para entrenar modelos de lenguaje de gran tamaño que demandan capacidad de computación distribuida. Además, con nuevas recetas para ajustar seis modelos distintos de DeepSeek, las empresas pueden implementar técnicas de ajuste fino supervisado y adaptaciones de bajo rango de manera eficiente.
Un caso práctico destacado es el uso de estos modelos en el sector salud, para desarrollar aplicaciones que faciliten la comprensión de información médica compleja por parte de los pacientes. Este ajuste fino del modelo DeepSeek-R1 Distill Qwen 7b, apoyado en un conjunto de datos específico del sector, demuestra cómo se puede mantener la precisión clínica requerida.
Al cierre de este ciclo de ajuste, se registró un aumento significativo en la eficiencia del modelo adaptado, con mejores métricas ROUGE, lo que sugiere que extender la duración del entrenamiento podría conducir a mejoras de rendimiento adicionales. Este progreso destaca no solo la innovación en la personalización de inteligencia artificial, sino también el potencial de optimizar los recursos computacionales en el ámbito empresarial.