En un entorno donde el entrenamiento de modelos de inteligencia artificial es cada vez más exigente y costoso, Amazon ha anunciado un avance trascendental con su sistema de entrenamiento sin puntos de control en Amazon SageMaker HyperPod. Este desarrollo responde a las limitaciones de los métodos tradicionales de recuperación basados en puntos de control, especialmente problemáticos en modelos que superan los billones de parámetros. Las constantes expansiones de los clústeres de entrenamiento, que ahora cuentan con miles de aceleradores de inteligencia artificial, han evidenciado lo perjudicial que pueden ser incluso las interrupciones menores, que conllevan costos y demoras significativos.
El nuevo enfoque de Amazon promete replantear el manejo de errores durante el entrenamiento, introduciendo una metodología que permite la recuperación de estado entre nodos del sistema. Este cambio ha permitido reducir drásticamente el tiempo de recuperación, pasando de intervalos de 15 a 30 minutos a menos de 2 minutos, según indican estudios de validación en producción. Esta innovación no solo mejora la eficiencia, sino que también propicia un entorno de producción más efectivo, logrando un 95% de eficiencia en clústeres con miles de aceleradores.
Dentro de este contexto, el concepto de «goodput» ha ganado protagonismo; este término mide el trabajo útil realizado en comparación con la capacidad teórica máxima de un sistema de entrenamiento. La caída del sistema y los sobrecostos de recuperación afectan negativamente al «goodput», especialmente en el entrenamiento de modelos grandes, donde tanto las frecuentes caídas como los prolongados tiempos de recuperación pueden significar pérdidas de millones de dólares al año.
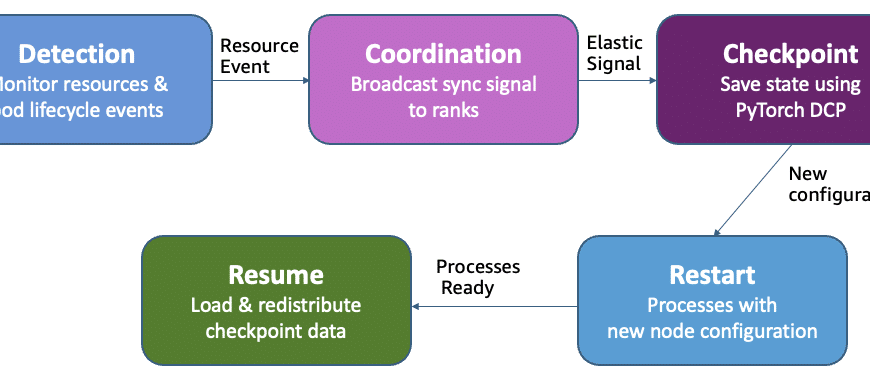
Tradicionalmente, la recuperación se basaba en guardar periódicamente puntos de control, reanudando el trabajo desde el último estado almacenado en caso de fallos. Este proceso no solo es complejo y largo, sino que cualquier error en un GPU o fallo de hardware podría detener todo el clúster de entrenamiento, llevando a extensos periodos de inactividad.
Por el contrario, el entrenamiento sin puntos de control de Amazon se basa en recuperar rápidamente el estado del sistema mediante el uso de pares en buen estado, evitando las operaciones de almacenamiento y los reinicios completos. Este método consiste en componentes que trabajan de manera autónoma para asegurar una recuperación rápida y sin intervención humana frente a errores.
La efectividad de este enfoque ha sido comprobada en diversas configuraciones de clúster, mostrando mejoras dramáticas en tiempos de recuperación y una reducción considerable de las inactividades, incrementando directamente el «goodput». Amazon ha demostrado que es posible alcanzar más del 95% de «goodput» incluso en clústeres que integran miles de aceleradores, marcando un progreso significativo en la eficiencia del entrenamiento de modelos.
A medida que la industria de la inteligencia artificial progresa, herramientas y métodos como estos representan un avance crucial en la optimización de procesos y la reducción de costos, permitiendo que el entrenamiento de modelos sea más eficiente y menos vulnerable a interrupciones mayores.