La reciente adopción de modelos de lenguaje de gran escala (LLMs) ha revolucionado la interacción tecnológica a nivel global. Sin embargo, la implementación a gran escala de estos modelos presenta desafíos significativos, especialmente en cuanto a latencia, rendimiento y costos. Esto es particularmente evidente durante eventos de alta demanda como el Amazon Prime Day, donde Rufus, el asistente de compras impulsado por inteligencia artificial de Amazon, debe afrontar una carga masiva cumpliendo con estrictos requerimientos de latencia y rendimiento.
Rufus está diseñado para optimizar la experiencia de compra de los consumidores, proporcionando respuestas rápidas y precisas a las consultas sobre productos. Para lograr esto, el sistema depende de un modelo de LLM para generar respuestas y un modelo de planificación de consultas que organiza y recupera información eficientemente. La sinergia entre estos componentes es crucial, especialmente en contextos de alta demanda donde la generación de texto necesita iniciar una vez completada la planificación de consultas.
En vísperas del Prime Day 2024, Rufus enfrentó la tarea de gestionar millones de consultas por minuto, generando miles de millones de tokens en tiempo real y manteniendo un compromiso de latencia de 300 ms. Para superar estos desafíos, se revalorizó la implementación de LLMs a gran escala, abordando cuellos de botella en costos y rendimiento.
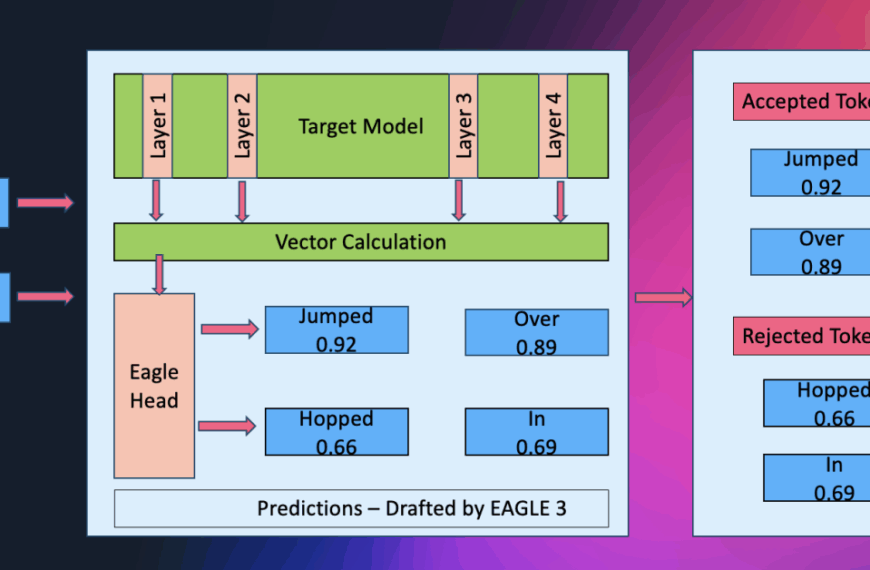
Un avance clave fue la implementación de la decodificación paralela, que permitió a Rufus generar múltiples tokens simultáneamente, superando las ineficiencias del enfoque secuencial tradicional. Rufus, al emplear chips de inteligencia artificial de AWS, no solo duplicó la velocidad de generación de texto, sino que también redujo en un 50% los costos de inferencia.
Los resultados fueron contundentes: Rufus demostró una capacidad de respuesta mejorada, elevando significativamente la experiencia del cliente. La combinación de decodificación paralela y tecnologías AWS facilitó un manejo eficiente del tráfico máximo sin comprometer la calidad de las respuestas.
Este avance destaca el potencial de las soluciones de inteligencia artificial para crear experiencias de compra más eficientes y fluidas. La futura integración con el marco Neuronx-Distributed Inference (NxDI) y los chips de AWS promete escalar y economizar aún más los LLMs, abriendo nuevas oportunidades para futuras aplicaciones en inteligencia artificial.